What is schema.org micro markup, and why do you need it?
- Home
- Knowledge Sharing
- What is schema.org micro markup, and why do you need it?
What is schema.org?
Schema.org is a website that acts as a library for different micro markups that can be applied to website pages. Markups can be used to inform search engine bots about important information that is useful/actionable for users such as shipping details, product pricing, refund policy, SKU #, manufacturer information, service areas, and so much more. Using this data, search engines generate extended snippets in their search results.
The schema.org dictionary has been recognized by search giants such as Google, Bing, and Yahoo. This is how a page with the prescribed micro markup looks in its output:
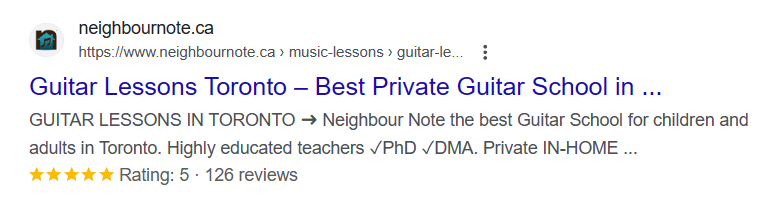
Besides Schema there are other kinds of micro partitions - each with different purposes.
Open Graph - Micro markup is a practical tool for customizing the display of social media posts. It ensures the correct presentation of your article, including the title, description, and image, when shared on platforms like Facebook, Twitter, and Telegram.
Microformats - This is a website created in 2007. It is suitable for marking up products, reviews, contact information, and other types of content. Although originally meant to be used more actively, it has drawbacks and must be developed, making it inferior to Schema.org.
Dublin Core - Libraries and museums use this markup dictionary, which allows for the description of books and museum exhibits.
The Difference Between a Dictionary and a Syntax
A dictionary is a set of classes and properties that describe a page's content type, and convey critical information. Its vocabulary can be compared to a language - for example, English, Schema.org, Open Graph, and Dublin Core are all dictionaries.
Now, let's talk about syntax. In web development, syntax is the method used to specify dictionary entities and properties in the HTML code of website pages. If a dictionary is like English, then syntax is akin to Latin, the language used to define the structure of English words.
The syntax options that are used for Schema.org markup include:
What is the difference between sites with and without markups?
Snippets on search pages show sites that have implemented micro markup. Here are two snippets from the same site, the first one with micro markup, and the second without it.
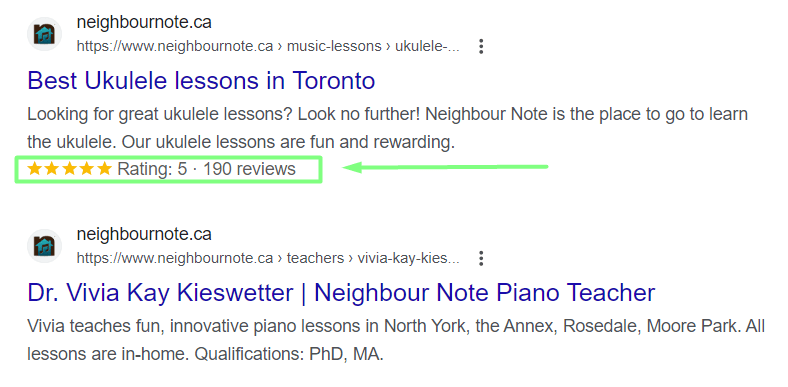
With the help of micro markups, prices are displayed in product page snippets:
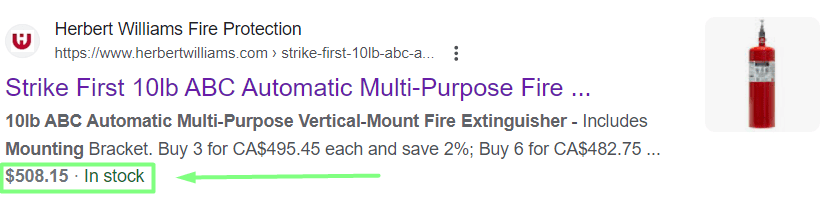
One more example - this first snippet implements breadcrumb micro markup, while the second snippet has no such markup:
Why Does This Matter?
This tool helps improve the ranking results of sites across all types of content. It is used when publishing formats such as:
- Texts
- TV series
- Cafes
- Small regional companies
- Programs
- Products
- Book reviews
- Movies
- Events
While there are thousands of types of markups, Schema Markup is still the best option for generating rich snippets. If you have a themed website, you're likely to find built in schema options – in fact, it's been proven that companies using Schema Markup for their websites have higher rankings in search results across the board.
According to recent studies, a website with markups will be placed four positions higher than one without it. This not only leads to an improved result, but there also appears to be a direct correlation when it comes to reassurance about the effectiveness of Schema Markups.
Statistics show that a third of Google search results use rich snippets in conjunction with Schema micro markups. However, search metrics state that only 0.3% of sites combine these markups - and that hundreds more sites underestimate the potential of this optimization tool.
What is the Schema.org dictionary?
A micro markup dictionary consists of entities (e.g., Products) and properties that describe entity parameters (e.g., SKU, price, availability, etc.).
The whole list of entities and documentation is available on the official schema.org website.
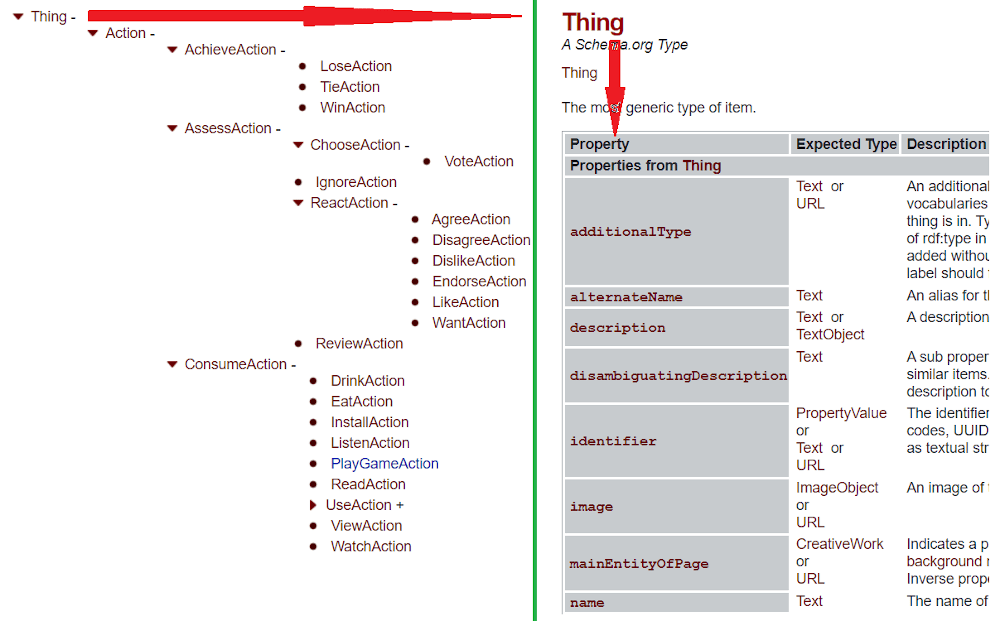
The screenshot shows some of the entities (on the left) and properties of the entity (on the right side of the screenshot)
Some of the most popular examples include:
Product
An entity used to mark up any product or service, such as a pair of sneakers, a concert ticket, or a car rental. An entity of this type has many properties that allow you to convey more information about the product/service: name, rating, brand, colour, category, width, height, weight, SKU, etc.
Event
An entity designed specifically to describe events that occur at a particular time and place: concerts, lectures, festivals, and more. Schema.org provides a variety of Event entity types, each tailored to a specific event - for instance, a business event (BusinessEvent), a festival (Festival), and a sports event (SportsEvent), among others.
Recipe
This entity is easy to use for marking up recipes. Its properties allow you to easily markup cooking time, calories, a list of ingredients, and step-by-step instructions, making your recipes more accessible and engaging.
Review
Entity properties - ratings and the "body" of the review.
Optimal syntax
There are three kinds of syntax that are suitable for Schema.org:
- RDFa
- Microdata
- JSON-LD
While the first two have several drawbacks and are losing popularity, JSON-LD is becoming the most frequently used syntax.
Google recommends using JSON-LD, which is simple and compact, instead of RDFas, microdata, and other syntaxes.
JSON-LD
Now, let's talk about what syntax looks like, and what rules apply.
JSON-LD, in its basic form, looks like this:
<script type=“application/ld+json">
{
//this is where the elements are placed
}
</script>
This construction is a framework, which is always there by default (like <html>, <head> and <body> tags in the structure of any HTML page). Inside the framework is the micro markup code, which contains necessary data: entity, properties and their values.
Here is what this markup looks like:
<script type=“application/ld+json">
{
“@context": “ https://schema.org/ ", //the markup dictionary - Schema.org is specified here
“@type": “Product", //the entity - product is declared.
“name": “iPhone", // property - the name of the product.
“image": “ <img src=“https://site.ca/iphone10.png“>“, // product image URL
“description": “iPhone 10", // description
“brand": “Apple", // brand-manufacturer
“aggregateRating": { // product rating
“@type": “AggregateRating",
“ratingValue": “5", //average rating
“ratingCount": “56" //number of user ratings
}
}
</script>
It's important to note that micro markup does not guarantee the search will display an extended snippet with all the data specified in the markup. Nevertheless, search robots will still consider past data, and will be able to understand the content of the page better.
How to do JSON-LD markup
Manual markup in JSON-LD (and in any other syntax) is a routine, time-consuming task, and carries with it the risk of making a mistake. Luckily, you can simplify the task by using JSON-LD generators:
-
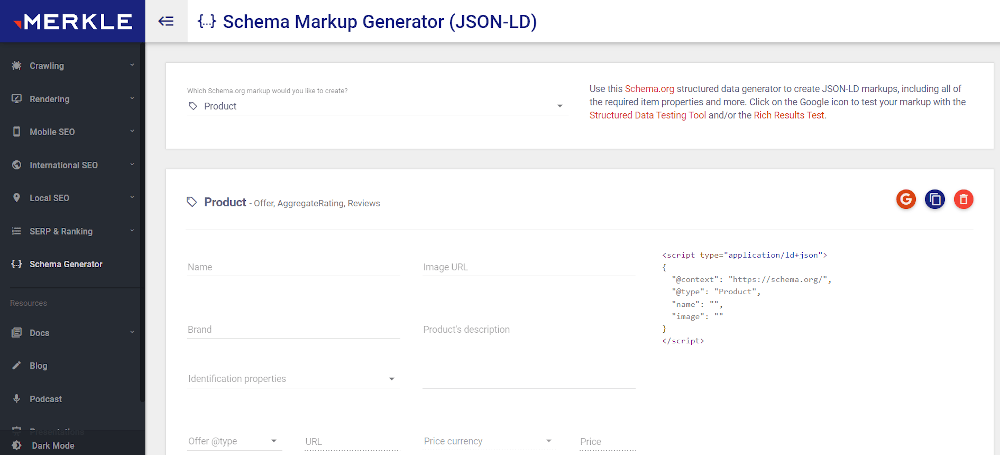
technicalseo.com
is a simple generator where you can markup the most commonly used entities (Article, Breadcrumbs, Event, FAQ page, Product, etc.). Select the desired entity from the drop-down list and specify your desired property values.
-
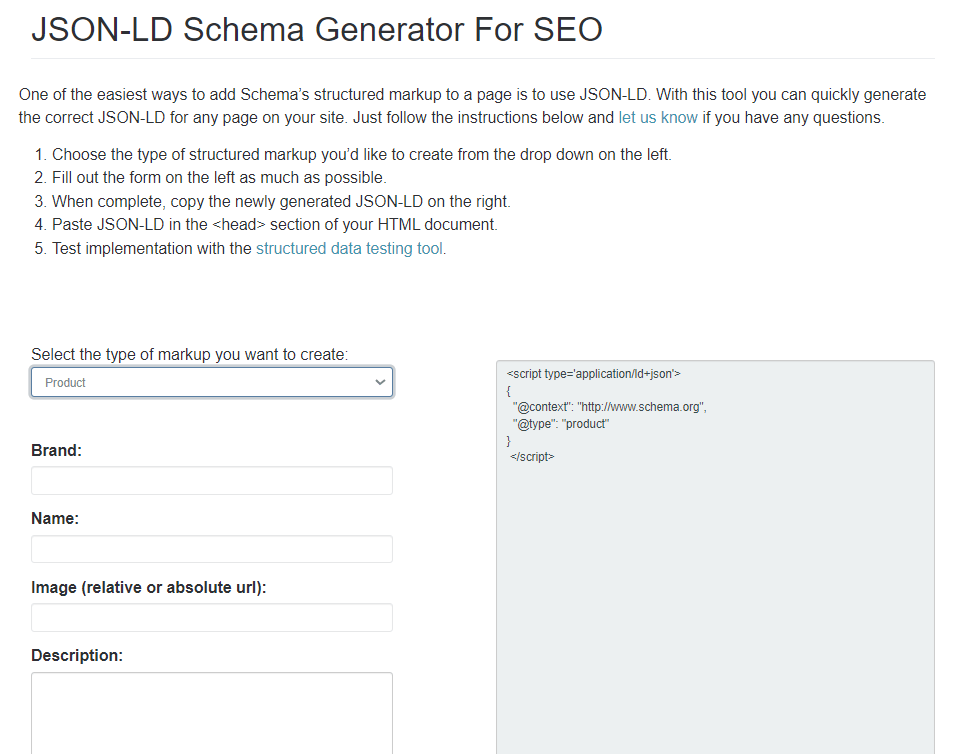
hallanalysis.com
is a simple and free service. At the time of writing, it can create markups for up to seven entities.
Markup validation
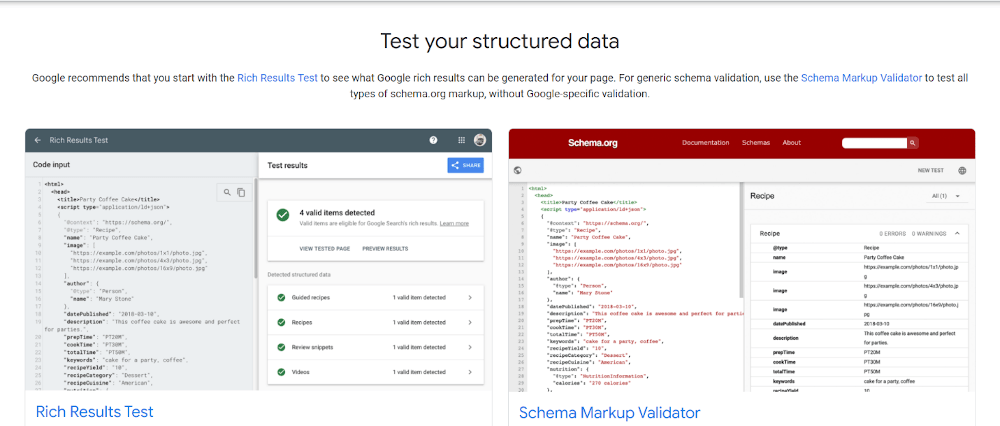
Syntax must be correct and error-free when creating micro markups. Even if you generate JSON-LD using special plugins or services, don't rush to upload the code to your site - check it for validity first.
To check your code, use validators from Google's search engine and Schema.org, and keep in mind that validation should be performed on two validators before uploading code to your site:
Where to insert JSON-LD?
If the code is valid (the validator found no errors), you can safely add the markup to your site. To do this, insert the code between the and tags on the landing page.
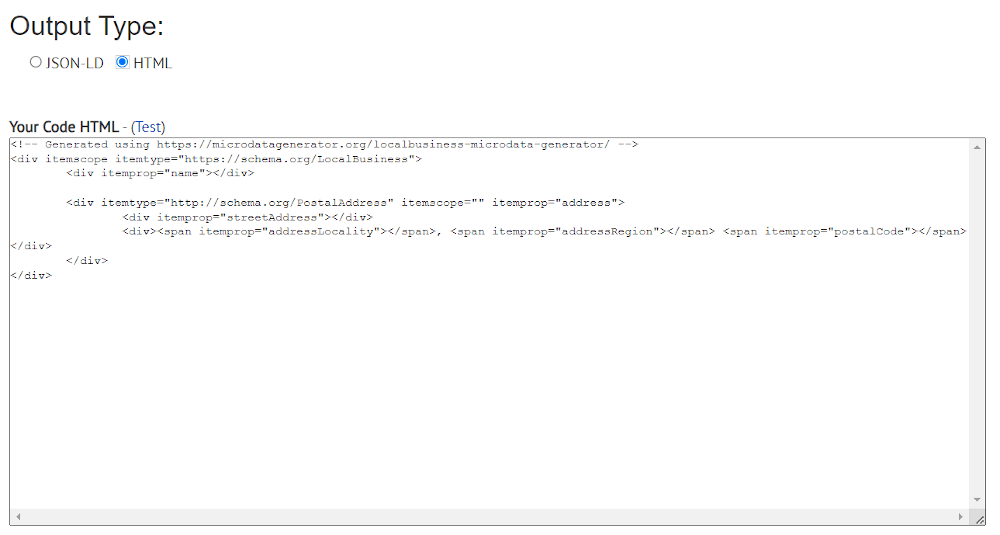
Microdata
Microdata uses the HTML markup language (JSON-LD uses JavaScript). Working with this syntax is more complicated, as the markup code must be written in the content body.
Microdata is based on three attributes:
- itemscope - indicates that an item (entity) is specified in the block (<div>...</div>);
- itemtype - indicates the type of the entity;
- itemprop - shows the properties of the entity.
Here's what it looks like:
<h1 itemprop=«name»>Joker</h1>
http://schema.org/Person »>Directed by:
<span itemprop=«name»>Todd Phillips</span>
(DOB <span itemprop=«birthDate»>December 20, 1970</span>)
</div>
<span itemprop=«genre»>Science fiction</span>
<a href=«../movies/interstellar-2-trailer.html» itemprop=«trailer»>Trailer</a>
</div>
Writing such code manually can be draining and time consuming, eating away at your time and energy with repetitive tasks.
Microdata Generation Service
The good news is that when it comes to microdata generation service needs, there exist exceptional services:
-
htmlstrip.com
is a free generator for markup, allowing you to create markups in JSON-LD syntax,
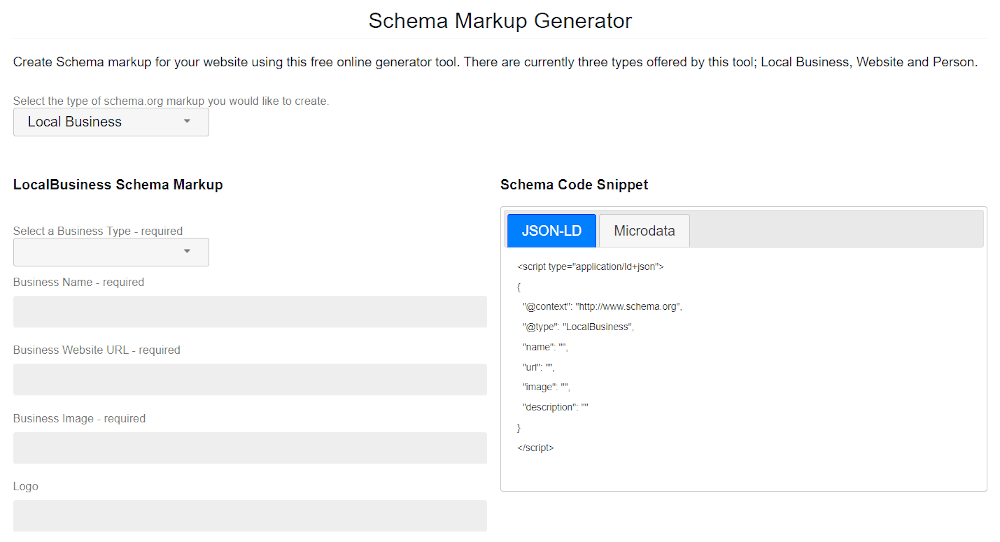
-
Local Business Schema Generator
is a narrowly focused generator. It can generate microdata or JSON-LD format markup for one entity, such as Local Businesses.
Is it worth implementing micro markup on your own and without code knowledge?
We recommend not taking on this task yourself. If your programming knowledge is at an initial level, it is better to leave this task to a specialist - otherwise, you may cause problems for your code.
Conclusion
Schema.org is an extensive vocabulary that can describe data and provide search engine robots with detailed information about products, services, and other entities:
- Micro markup is a game-changer - it enhances the appearance of the snippet in the search engine, making it more attractive and informative. The result? A potential boost in your click-through rates, which is always exciting for any digital marketer or website owner.
- If you promote only on Google, use the search engine's recommendation and mark up data in JSON-LD.
- Google becomes more straightforward: the data marker in the Search Console can help you implement markups in a few clicks (without code, plugins, or third-party services).
- Don't write code manually - use generators, as they will save you time and avoid errors.
- Check errors with validators.
Schema.org Micro Markup FAQs
How did schema.org and Google’s handling of structured data change in 2025?
In 2025, schema.org moved into the 29.x releases, adding new types and properties and cleaning up earlier patches, which expanded what you can describe with structured data. You can see the release history at https://schema.org/docs/releases.html. In the same year, Google announced that it would phase out several lesser used structured data features in order to simplify the search results page, while keeping support for core rich result types. These shifts mean that in 2026 you need to focus your markup on high value types that still drive rich results and machine understanding, instead of trying to tag everything just because it exists in the vocabulary.
How does schema markup help large language models understand a website in 2026?
Large language models such as Gemini, GPT style systems and Claude primarily read raw text, but schema markup gives them an extra layer of hints about what each part of the page represents. Well formed JSON LD can clarify which strings are products, reviews, events, prices or organizations, which reduces ambiguity when answers are generated. Several GEO and AI content studies in 2025 highlighted that machine readable structure improves how reliably brand information is reused inside generative answers, even if the models are not strictly parsing every field. This does not replace clear prose, yet it makes it easier for models to treat your site as a trustworthy, well labeled source.
If Google is removing some rich results, is schema markup still worth the effort?
Google’s 2025 updates removed support for a number of niche structured data types, but confirmation from Search Central events and documentation is that high quality schema still helps both classic results and AI experiences. Rich snippets are now concentrated around formats that users actually interact with, such as products, FAQs, local business information and key reviews. Even when a specific badge disappears, valid markup continues to feed ranking systems, knowledge panels and AI Overviews. In 2026 the focus is less on chasing every possible icon and more on using schema to strengthen the semantic clarity of your most important pages.
What is the connection between schema markup and Generative Engine Optimization (GEO)?
Generative Engine Optimization treats AI systems as an additional audience that needs clear, machine readable signals. GEO playbooks released in 2025 repeatedly list structured data and schema as core technical elements, alongside internal linking and navigation clarity. When your pages expose consistent entities, relationships and attributes, AI summary engines can assemble accurate, context aware answers that credit your brand. In practical terms, schema.org becomes part of the same toolkit as headings, copy and links when you plan how to appear in AI Overviews and chat style search.
How should schema implementation priorities change for 2026?
Instead of trying to mark up every possible field, concentrate on entity types that tie directly to revenue and discovery such as Product, Service, LocalBusiness, Article, Event and FAQPage. These formats are still mentioned in Google’s current guidance about succeeding in AI enhanced search and are widely used in rich snippets. For each key page, the goal is to give search engines and LLMs one unambiguous description of what the page is about, who it is for and how it relates to the rest of your site. This mindset keeps your schema lean, purposeful and easier to maintain.
Do I need to change how I write JSON LD so it works better with LLMs?
The underlying syntax of JSON LD does not need to change for LLMs, but the way you choose values should assume a model might quote them directly. Short, human readable names, clean descriptions and realistic ratings reduce the risk of awkward AI snippets. Experiments shared in 2025 showed that models sometimes ignore overly technical or spammy fields even when the JSON is valid. Treat your structured data as another surface where your brand voice and factual accuracy are on display.
How does schema.org help with Google AI Overviews and AI Mode?
Google has stated that structured data supports both traditional results and newer AI features by making content easier to understand and categorize. AI Overviews often pull from pages that combine strong content with clear signals about entities, authorship and freshness, all of which can be reinforced with schema. While markup alone will not guarantee inclusion, it improves the odds that your pages qualify when the system needs sources that match a specific entity type, such as a product or local business. In 2026 it is one of several inputs that help your site stay visible as Google experiments with AI only interfaces.
Can schema markup improve how my content is used in non Google LLM search tools?
AI search tools like ChatGPT search, Gemini based assistants, Perplexity or other LLM powered engines crawl the open web and look for consistent patterns to anchor their answers. Structured data is not the only signal they use, but it adds a layer of machine oriented clarity that is easier to reuse than plain text alone. GEO focused resources now treat schema as a shared foundation that benefits multiple generative platforms at once, not just Google. This means a well marked up site can be cited more reliably across different LLM ecosystems.
Are there risks to overusing or misusing schema markup after the 2025 changes?
Overly aggressive markup that does not match visible content, such as fake reviews or exaggerated offers, can lead to manual actions or simple ignoring of your structured data. Google’s move to retire some structured data types in 2025 signalled a preference for leaner, user first implementations that add real value rather than decoration. LLM based engines are also more likely to downweight sources that appear manipulative or inconsistent between markup and main text. Treat every field as something that a human or AI might read aloud and you will naturally avoid many pitfalls.
How should small teams keep schema markup healthy in 2026 without a full dev squad?
A practical approach is to standardize a handful of JSON LD templates for your main page types and reuse them through your CMS, instead of hand coding every instance. Visual schema generators and lightweight plugins can produce the base code, while periodic validation checks catch errors before they accumulate. For GEO and AI search readiness, the most important task is to keep key entities current when products, services or locations change, rather than chasing every new experimental schema type. A short quarterly audit that reviews coverage, error reports and alignment with your current offers is usually enough to stay in good shape.





